En un nuevo “paper” titulado “Dancing Under the Stars: Video Denoising in Starlight“, el equipo de inteligencia artificial de Intel Labs y UC Berkeley detallan cómo desarrollaron un nuevo sistema de “deep learning” (redes neuronales artificiales), que por primera vez es capaz de eliminar el ruido de imagen en videos que han sido filmados en condiciones extremadamente oscuras solo bajo la luz de las estrellas.

Por Homer Díaz
Durante las noches, la luna provee un nivel de iluminación entre 0.05 a 0.3 lux (Lux = unidad de medida de intensidad luminosa), y en noches sin luna -solo bajo la luz de las estrellas- la iluminación es inferior a 0.001 lux.
Los seres humanos necesitamos un nivel de iluminación de por lo menos 1 lux para ser capaces de ver en la oscuridad; los gatos solo necesitan 0.125 lux, es decir pueden ver 8 veces mejor de lo que las personas ven en la oscuridad; y las abejas carpinteras apenas necesitan 0.001 lux. Mientras que para grabar videos por las noches, las cámaras digitales CMOS de alta sensibilidad requieren por lo general un nivel de iluminación de por lo menos 0.1 lux (nivel de luz que puede proveer la luna aproximadamente).
Fotografiar en entornos muy oscuros (noches sin luna) es sumamente difícil; por tal razón los fotógrafos emplean técnicas de fotografía como por ejemplo tiempos de exposición prolongados (20 segundos o más) con la finalidad de capturar suficiente luz de la escena que desean fotografiar. Esta técnica funciona bien para imágenes fijas, pero no para tomas de video.
Como técnica alterna para poder grabar videos por las noches, los camarógrafos aumentan la ganancia de la cámara de tal manera que cada píxel sea más sensible a la luz; pero por otro lado, esto trae como consecuencia la aparición de ruido de imagen en el video. Con esta técnica, se pueden percibir objetos en movimiento a través de la cámara, pero el ruido causa un efecto granulado o distorsionado en la imagen de video.

{kind=link}
A lo largo de los años, se han desarrollado algoritmos que eliminan el ruido de imagen (“denoisers”) con la finalidad de mejorar la calidad de video (como por ejemplo el V-BM4D, desarrollado en 2012). En algunos casos, estos son efectivos eliminando ruido; sin embargo, la mayoría de estos algoritmos clásicos han sido desarrollados tomando en cuenta solo ciertos modelos de ruido como por ejemplo ruido estadístico Gaussian o ruido estadístico Poisson-Gaussian.
Al ajustar una cámara a niveles muy altos de ganancia para capturas en ambientes extremadamente oscuros, el ruido de imagen, por lo general, no es ruido gaussiano (Gaussian) ni lineal, más bien es un ruido difícil de interpretar. Por lo tanto, estos algoritmos clásicos podrían no ser tan efectivos eliminando el ruido en entornos sumamente oscuros.
En los últimos años, otros tipos de algoritmos basados en “deep learning” (como por ejemplo el FastDVDNet, desarrollado en 2020) han demostrado ser muy eficaces eliminando ruido de imagen en videos que fueron filmados en entornos con poca luz (del rango de 0.1 – 0.3 lux). A diferencia de los algoritmos clásicos, en lugar de asumir ciertos modelos de ruido estadístico, lo que se hace mediante “deep learning” -para situaciones extremadamente oscuras- es entrenar un “denoiser” (modelo que elimina ruido de imagen) utilizando como datos de entrenamiento varios pares de imágenes (limpias y con ruido) capturados por una cámara.
Sin embargo, el costo de entrenar un “denoiser” es muy alto ya que se necesitan realizar capturas de miles de pares de imágenes para usarlas como datos de entrenamiento. Además se requiere volver a realizar capturas de pares de imágenes usando varias cámaras, ya que es de suma importancia que estos datos de entrenamiento provengan de diferentes tipos de cámara porque el ruido de imagen varía de un sensor de cámara a otro.
Además, si bien es posible realizar capturas en la oscuridad de pares de imágenes de objetos estáticos (ajustando la exposición/ganancia de la cámara); realizar capturas de pares de imágenes de escenas en movimiento requiere adicionalmente una segunda cámara y técnicas de alineamiento, lo cual resulta sumamente complicado e impráctico.
Método
Como mencionamos anteriormente, el nivel de iluminación durante las noches con luna va del rango de 0.05 a 0.3 lux. Sin embargo, los científicos y autores del “paper” Dancing Under the Stars: Video Denoising in Starlight, pusieron la mira en entornos por debajo de 0.001 lux (noches sin luna) con el objetivo de desarrollar un “denoiser” que por primera vez elimine el ruido de imagen en videos que hayan sido filmados a niveles extremadamente bajos de iluminación (milésimas de lux). Para alcanzar el objetivo de desarrollar un “denoiser” de esta naturaleza, el grupo de científicos lo logró en dos fases.
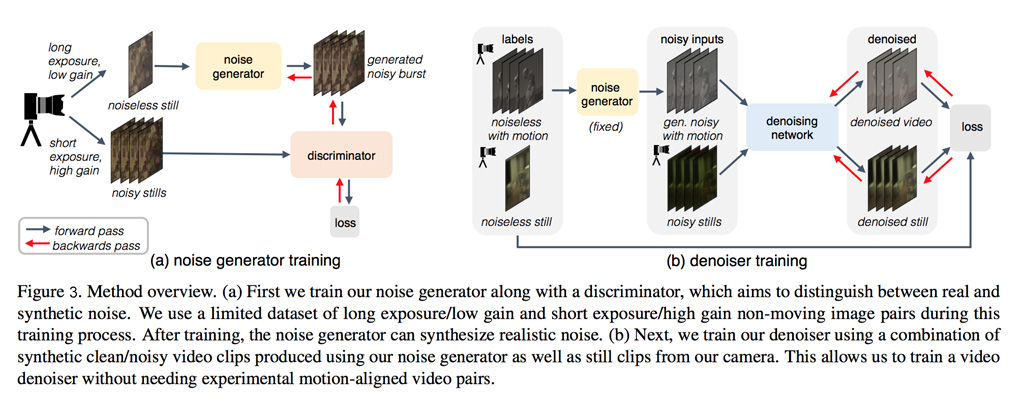
En una primera fase (Ver figura 3a), los científicos entrenaron un modelo generador de ruido de imagen (“noise generator”) de tal manera que el modelo aprenda a representar ruido de imagen a niveles sumamente bajos de iluminación. Y con el objetivo, al término del entrenamiento, que el “noise generator” sea capaz de generar pares de videos sintéticos o artificiales (limpios y con ruido) para entrenar un “denoiser” en una segunda fase.
Con el fin de que, durante el entrenamiento, el “noise generator” genere diferentes muestras de datos en cada “forward propagation”, el grupo de científicos empleó un tipo de arquitectura de red neuronal conocida como GAN (“Generative Adversarial Network“). Este tipo de arquitectura utiliza durante el entrenamiento dos redes neuronales denominadas “noise generator” y “discriminator” (Ver figura 3a), las cuales se “enfrentan” una contra la otra. Este “enfrentamiento” tiene la finalidad de que el “noise generator” genere sucesivamente (en cada “forward propagation”) nuevas muestras sintéticas (artificiales) que resulten cada vez más reales de tal manera que pasen inadvertidas a través del “discriminator”, cuya función es evaluar qué tan reales son las muestras sintéticas generadas por el “noise generator”.
Este “noise generator” solo necesitó ser entrenado con un número muy limitado de pares de imágenes (limpias y con ruido); y además, no se necesitaron técnicas adicionales de alineamiento de los videoclips (limpios y con ruido). Por tanto, este método -comparado con otros- resulta mucho más simple y no se requiere conseguir grandes cantidades de datos de entrenamiento.
En la segunda fase (Ver figura 3b), los científicos usaron el “noise generator” (completamente entrenado) para entrenar el “denoiser” que básicamente es otra red neuronal que se encarga de eliminar el ruido de imagen en video. Para el entrenamiento del “denoiser” se utilizaron como datos de entrenamiento una combinación de videoclips con ruido sintético o artificial (generados por el “noise generator”), así como también se utilizaron imágenes estáticas con ruido real.
Finalmente, los científicos pusieron a prueba su “denoiser” utilizando una serie de videos filmados a un nivel de iluminación de 0.0006 lux. Este “denoiser” pudo por primera vez eliminar ruido de imagen en videos que fueron filmados solo bajo la luz de las estrellas; y superó en calidad de imagen a los “denoisers” clásicos como el V-BM4D y a uno de los mejores “denoisers” basado en “deep learning” conocido como FastDVDNet (Ver figura 4).

En términos generales, este trabajo científico muestra la gran capacidad que siguen teniendo los modelos basados en “deep learning” (redes neuronales artificiales) para eliminar ruido de imagen en videos que son filmados en ambientes extremadamente oscuros. El grupo de científicos espera que este trabajo de investigación ayude a empujar los límites de la visión robótica hacia entornos extremadamente oscuros del orden de los 0.0006 lux, es decir una visión robótica nocturna aproximadamente 200 veces mejor que la visión nocturna de los gatos.
Para ver más detalles de este “denoiser” puedes revisar el “paper” Dancing Under the Stars: Video Denoising in Starlight que ha sido aceptado en la conferencia Computer Vision and Pattern Recognition 2022 (CVPR 2022) y se encuentra disponible en el portal arXiv.
Para obtener el dataset y el código del “denoiser”, visita el website del proyecto.
Este artículo ha sido escrito basado en el “paper” Dancing Under the Stars: Video Denoising in Starlight cuyos autores son Kristina Monakhova (UC Berkeley), Stephan R. Richter (Intel Labs), Laura Waller (UC Berkeley) y Vladlen Koltun (Intel Labs).